<< Part IV | This is Part V of a multi-part series on Bitcoin block propagation with IBLT.
Rusty Russell has dumped mempool data from 4 different nodes around the globe. It covers a week's worth of data. The purpose of the dumps was to get an idea on how similar the mempools are. The effectiveness of IBLTs is highly dependent on the similarity of mempools. The data covers blocks at height 352305 thru 353025. For every block and node, it will list:
- mempool-only: Transactions that are not in the block, but present in the mempool
- plus-transactions: Transactions present in the block, but not in the mempool
- zero-transactions: Transactions present both in the block and in the mempool
From this we can pretend that a node is receiving a block and that the plus-transactions are exactly the ones listed in the data. We can't say from this data alone what the set of minus-transactions (transactions that the receiver removes from the IBLT, but wasn't present in the IBLT) would be, but we assume that there are equally many minus-transactions as there are plus-transactions. The minus-transactions will be selected randomly from the mempool-only set.
Now, we use this as input to determine the IBLT sizes for several different failure probabilities:
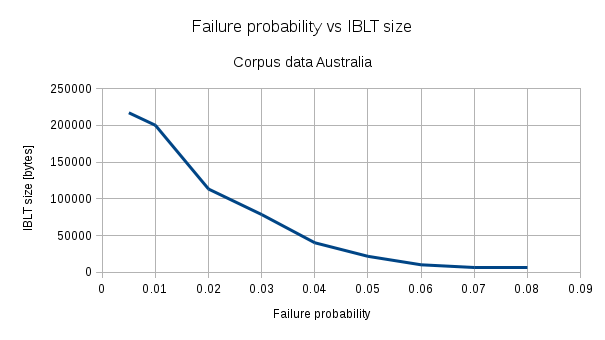
Some stats from the data set:
Average block size [Bytes]: 381891
Average tx count per block: 715
Sample count : 722 (One fork included)`This tells us that with an IBLT of size 21600 bytes, we could have successfully transferred 95% of the blocks to the Australian node. That's about 5.7% of the average block size. Also if we want to go super-small and if we can put up with 8% failure probability, we can use an IBLT of 5760 bytes or about 1.5% of the average block size
The result above is just a first step. There are several optimizations to be made to further shrink the IBLT:
- Added set: A set of hash prefixes that the sender can add to the message to signal "These transactions were added in spite of my fee hint"
- Removed set: A set of hash prefixes meaning "These transactions were excluded from the block in spite of my fee hint"
- Literal set: A set of transactions that the sender thinks is unlikely to be present in the receiver's mempool. The coinbase will be here, but probably also transactions that the sender didn't have when receiving the block.
In part VI of this series I'll show you results from scaling up the corpus data 10x, 100x and 1000x. Or if we have results from the above mentioned optimizations, I may decide to write about that instead. Stay tuned!